궁금했던 점
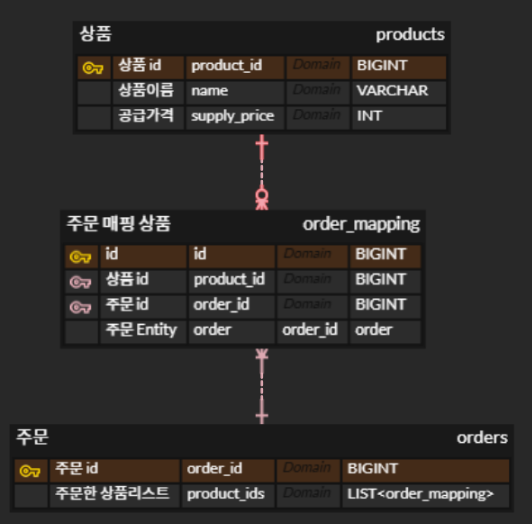
상황 주문 로직을 위해 "주문 테이블(Order)"과 "상품 테이블(Product)"를 구성했다.
어떤 주문에 어떤 상품이 담기는지를 구성하다보니 N:M구조가 되어,
중간 테이블 "주문 매핑 상품 테이블(Order_mapping)"을 중간에 두었다.
Order와 Order_mapping은 식별관계이고,Product과 Order_mapping 또한 식별관계이다.
식별관계인 테이블이 있다고 가정한 상황에서
Order_mapping의 PK가 복합키로 존재한다면 DB관리에 불편함이 있었다.
단일 PK로 레코드를 고유 식별가능하도록 PK를 추가한다면 여전히 식별관계인가?
NO => 비식별 관계이다.
구분 기준
두 테이블간의 관계가 자식 테이블의 기본 키(PK)에 영향을 미치는지에 따라 구분
이 글에서
부모 테이블의 기본키 = Parent PK
자식 테이블의 기본키 = Child PK
로 명명하겠습니다.
1. 식별 관계 (Identifying Relationship)
정의
Parent PK가Child PK에 포함되는 관계Child PK는Parent PK와 자식 자신의 고유 속성으로 구성됨Child PK= {Parent PK, 자신(Child)의 고유 속성 }
특징
Parent PK를 반드시 포함Child PK는Parent PK를 포함해야 함.- 즉, 부모의 존재가 자식을 "식별"하는데 필수적이다.
- 강한 의존성
- 자식 테이블은 부모 테이블에 강하게 의존하며,
부모 없이는 자식의 존재가 정의되지 않음.
- 자식 테이블은 부모 테이블에 강하게 의존하며,
- ERD 표현
- ERD에서 굵은 선으로 표현 됨
예제
- 부모 :
Order(주문 테이블) - 자식 :
OrderItem(주문 상세)
Order (부모 테이블)
------------------------
| order_id (PK) |
------------------------
Order_maaping (자식 테이블)
------------------------
| order_id (PK, FK) |
| product_id (PK) |
| quantity |
------------------------- 설명
OrderItem의orderId는 부모Order의 PK에서 상속받았으며OrderItem의 PK를 구성한다.OrderItem은Order가 존재하지 않으면 식별할 수 없다.
2. 비식별 관계 (Non-Identifying Relationship)
정의
Parent PK가Child PK에 포함되지 않는 관계Parent PK는Child PK로만 존재하며, 자식의 PK에는 영향을 미치지 않는다.
특징
Parent PK를 참조만 함Parent PK는 자식 테이블의 FK로만 사용되며,Child PK를 구성하지 않는다.
- 약한 의존성
- 자식 테이블은 부모 테이블에 약하게 의존하며,
부모 없이도 고유하게 식별될 수 있다.
- 자식 테이블은 부모 테이블에 약하게 의존하며,
- ERD 표현
- ERD에서 점선으로 표현 됨
예제
- 부모 : Order (주문 테이블)
- 자식 : OrderItem (주문 상세)
Order (부모 테이블)
------------------------
| order_id (PK) |
------------------------
Order_maaping (자식 테이블)
------------------------
| order_maaping_id (PK) | -- 자식 테이블의 고유 PK
| order_id (FK) | -- 부모 테이블의 FK
| product_id |
------------------------- 설명
order_item_id가 자식 테이블OrderItem에서 고유 식별자로 사용된다.order_id는 단순희 부모 테이블을 참조하는 자식 테이블의 외래 키로 존재- 부모의 존재 여부와 상관없이, 자식 테이블의
order_item_id만으로 레코드를 고유하게 식별가능
정리
| 특징 | 식별 관계 | 비식별 관게 |
| 자식 PK에 부모 PK 포함 여부 | 포함 | 미포함 |
| 의존성 | 부모 없이 존재 불가 | 부모 없이 존재 가능 |
| ERD표현 | 굵은 실선 | 점선 |
| 테이블 설계 | 자식 테이블의 PK가 복합 키로 구성됨 | 자식 테이블의 PK는 독립적인 단일키 가능 |
| 사용 사례 | 강한 의존 관계 (예: 주문과 주문 상세) | 약한 의존 관계 (예: 고객과 주문) |
Child PK가 복합키로 (Parent PK, 자식 테이블의 속성)으로 구성되어 있다면 -> 식별 관계
Child PK가 단일키로 고유 식별자 역할을 한다면 -> 비식별 관계
반응형
'Computer Science > Database' 카테고리의 다른 글
| [Database] N+1 문제 (0) | 2024.11.29 |
|---|